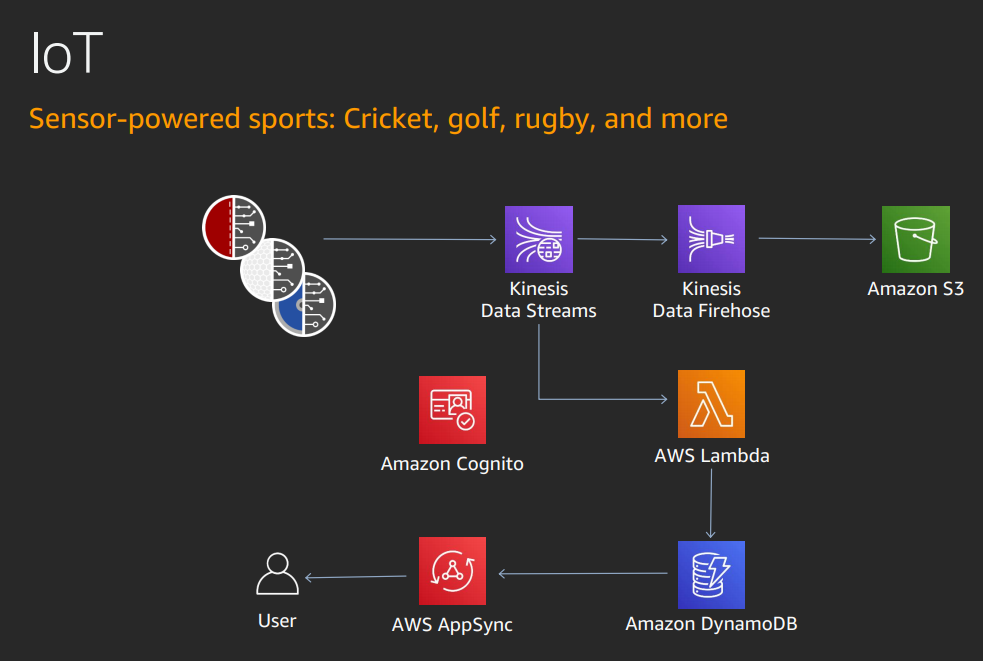
Goal is to make data widely available.
SQL. Slows down when reporting. Lots of data outside of database hard to report on. Hadoop for this data. But them more and more data. Need to analyse data at higher speed, and more data. Multiple languages used, people using various tools.
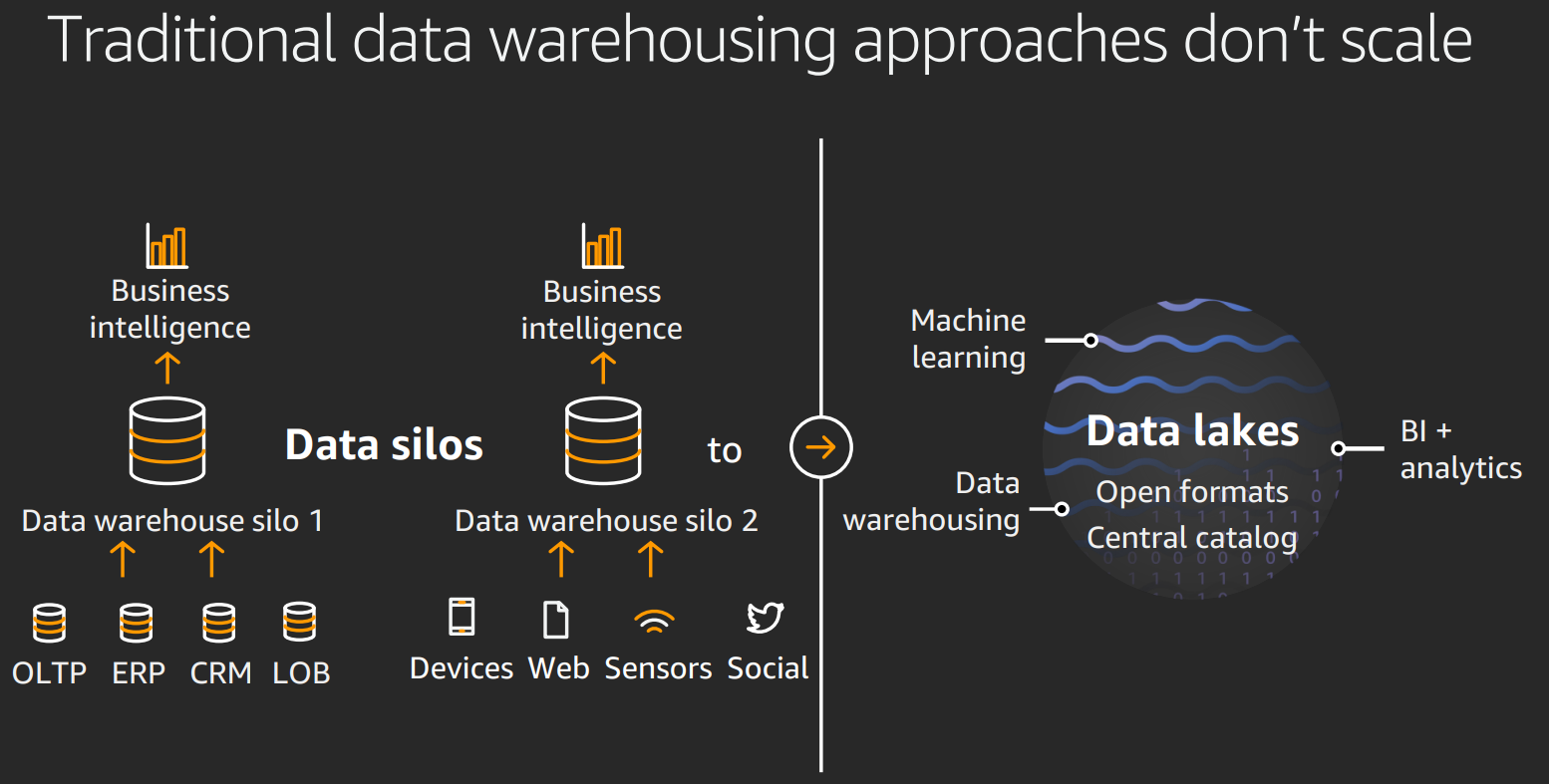
Data lakes is a centralised repository with a catalogue. Allows for self service and reporting. Easy plug in of analytical engines.
Possible to have an open source solution, but need lots of tools and open source. Apache, hadoop, hive etc. Many tools, hard to manage. Hard to update, security hard, cluster is mainly idle, no time to experiment.
Cloud is a better solution. Serverless. Some are open source, some are open source managed by AWS.
Easy to build on AWS: S3 for storage.
Only pay for storage, and compute when you use it.
Flexible pricing tiers, so e.g. use intelligent tiering so you can automatically move to data a cheaper tier if you don't access it for a month.
Security: lots of facilities for compliance, don't need to build yourself.
Comprehensive set of services: storage, analysis, data transformation and loading. Mainly based on open standards or open source, so that makes it easy away from AWS.

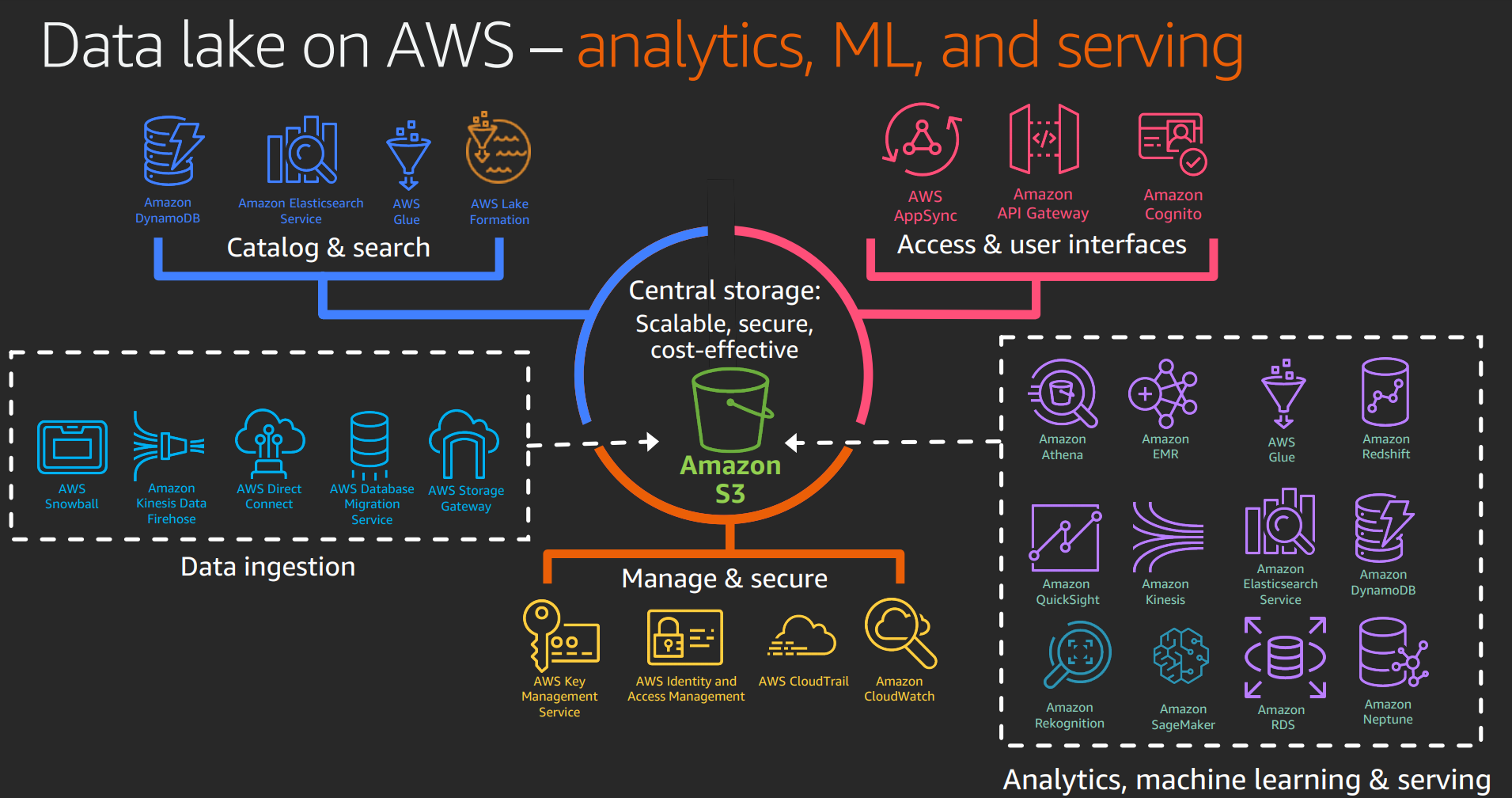 !
!
Amazon EMR: hadoop based automatic scaling
Amazon Redshift: warehousing
Amazon Glue: transformation
Amazon Athena: queries
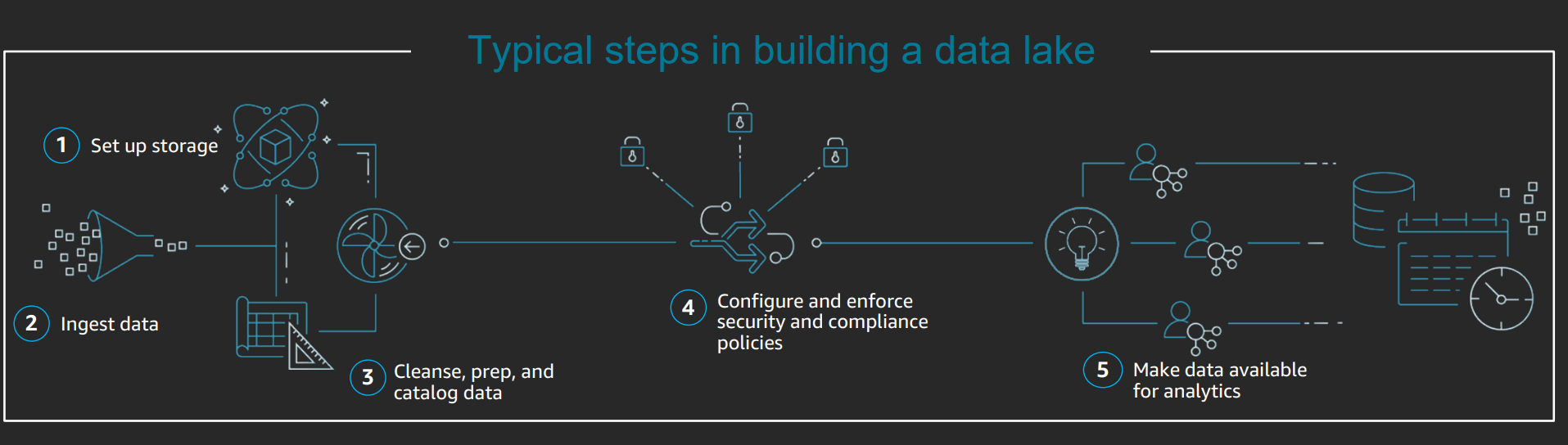
Pipeline architecture: start in raw data in S3, use amazon glue or EMR
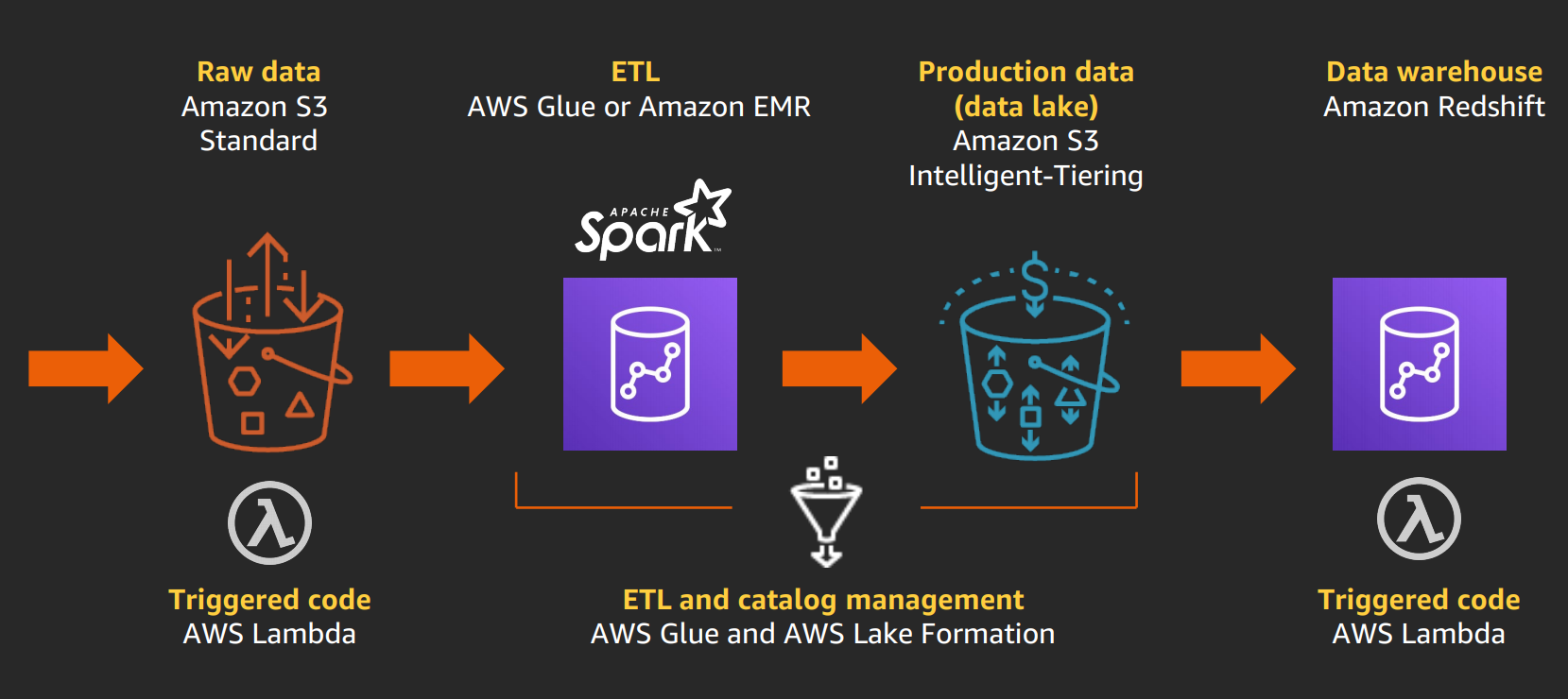
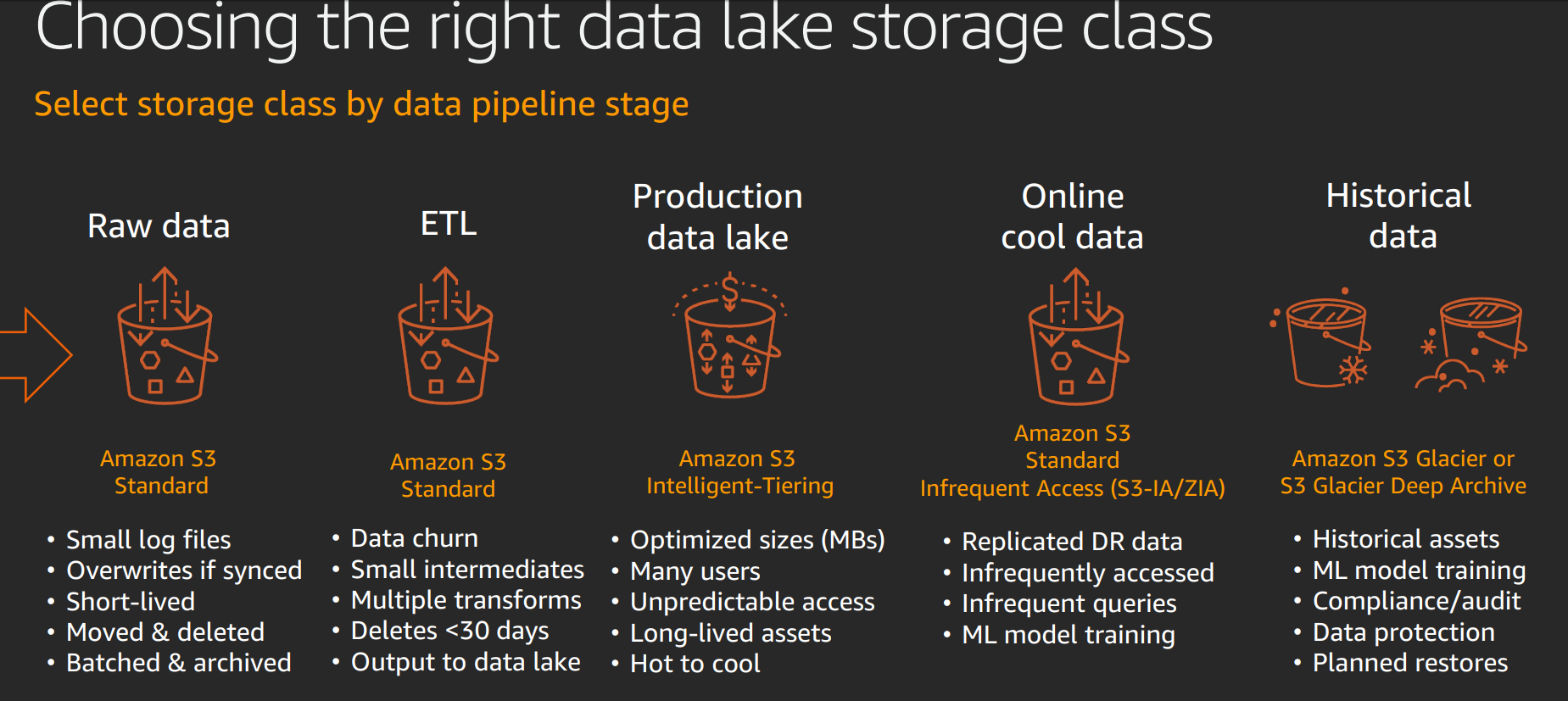
Use object tagging to flag data to apply secuity policy, archiving.
Batch operations
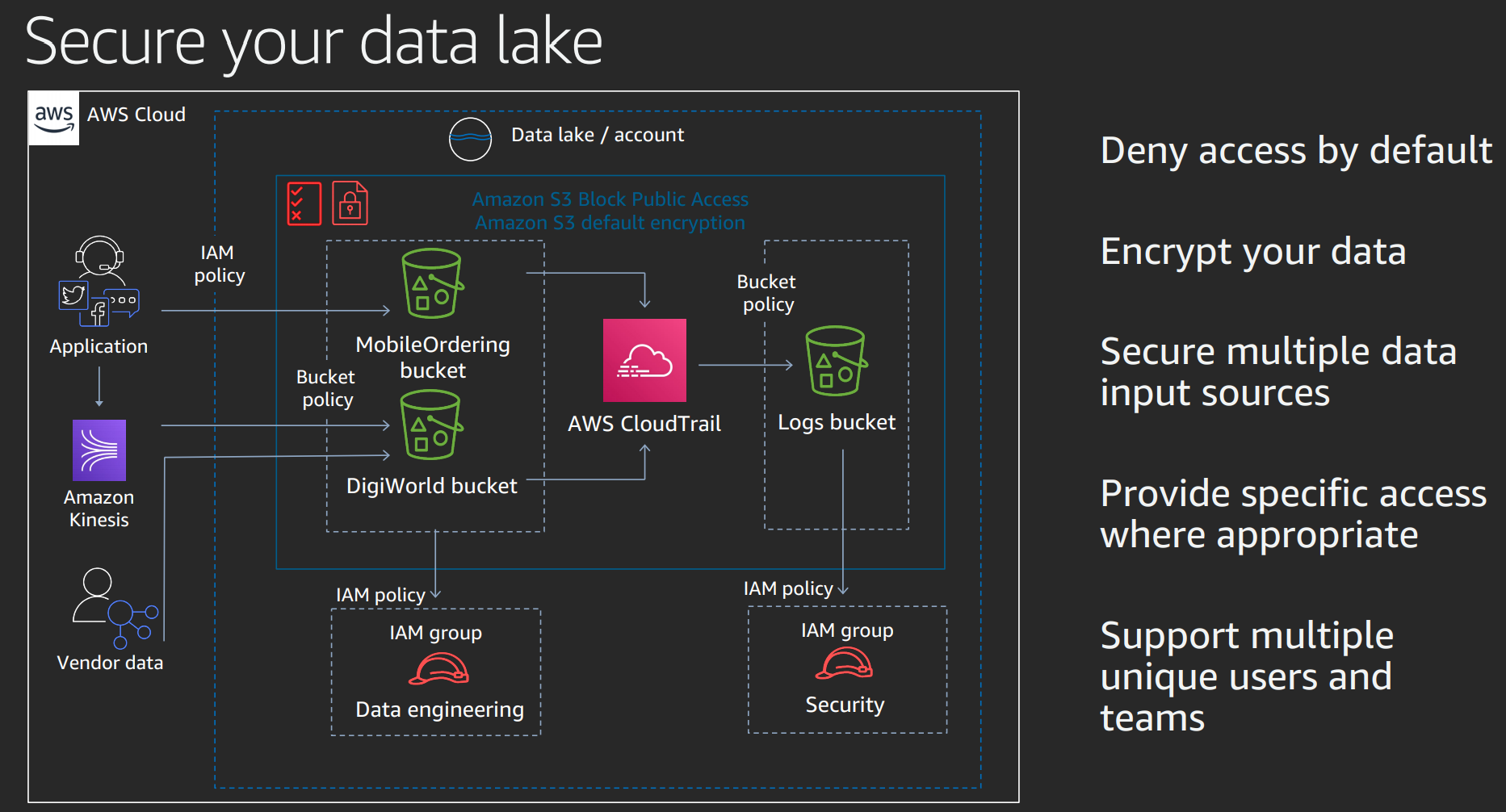
one stop shop for easy data lake.
Transforms, catalogues, enforces security, provides self service access to data.

Amazon RDS: move without changing applications. Reduce admin, get better performance. scalability, security.
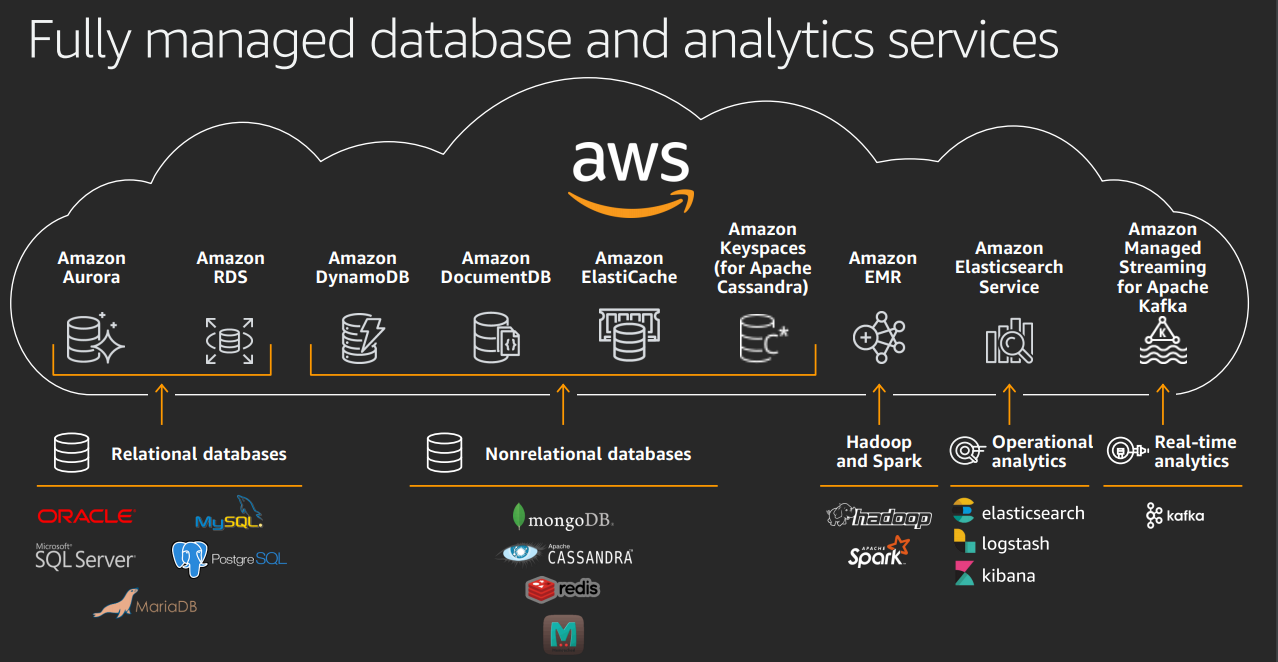
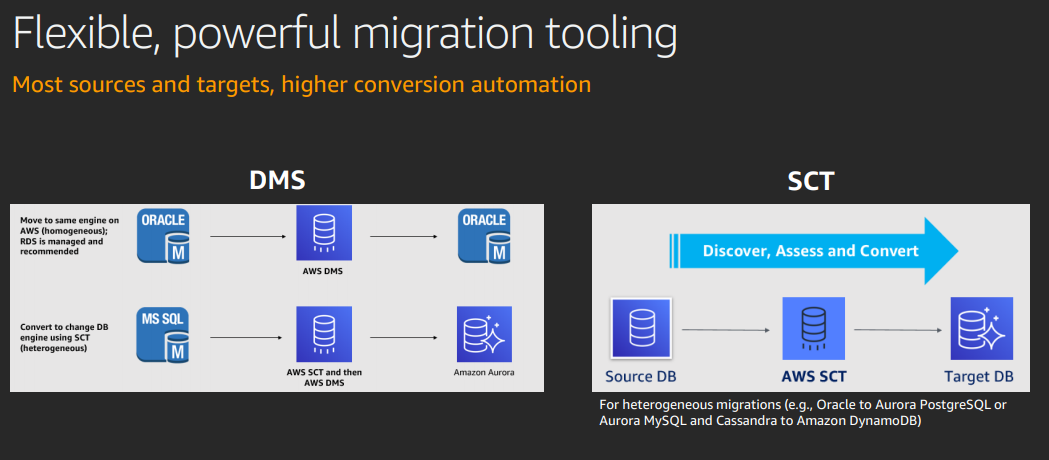
AWS databates nmigration services (DMS) - to move data.
Schema conversion tools (SCT) to go from one db to another - to move schema. Not 100% but simpler.
DMS can do replication. E.g. take an SQL backup, migrate, then apply more recent transaction logs.
Database freedom program to move from in house to AWS quickly, scale up and down cheaply.
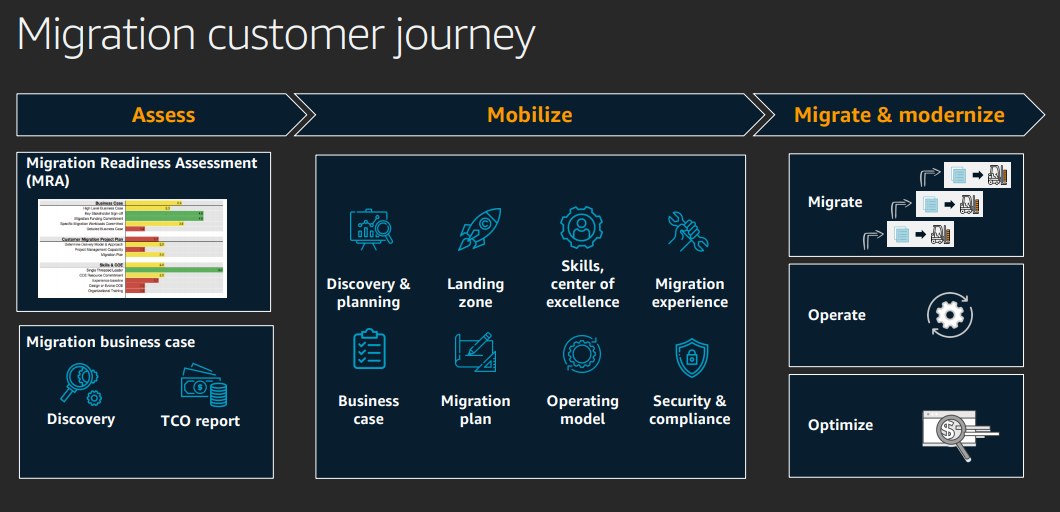
Issues:
A technical platform to store data with various facilities and capabilities.
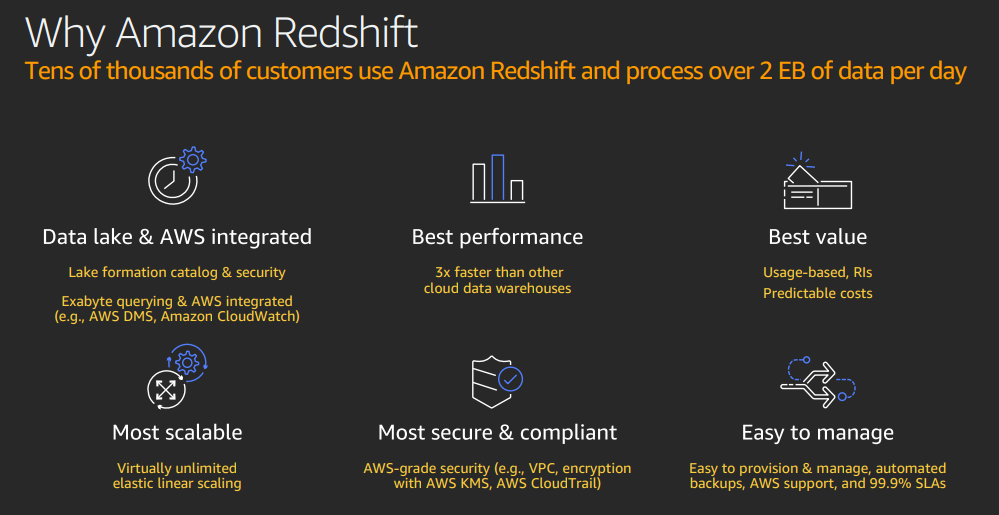
Allows data warehouse and data lake interactions
Business data in data warehouse, structured, relatively static. Complex analytic queries.
Data lake for event data, allows data in multiple formats, less structured.
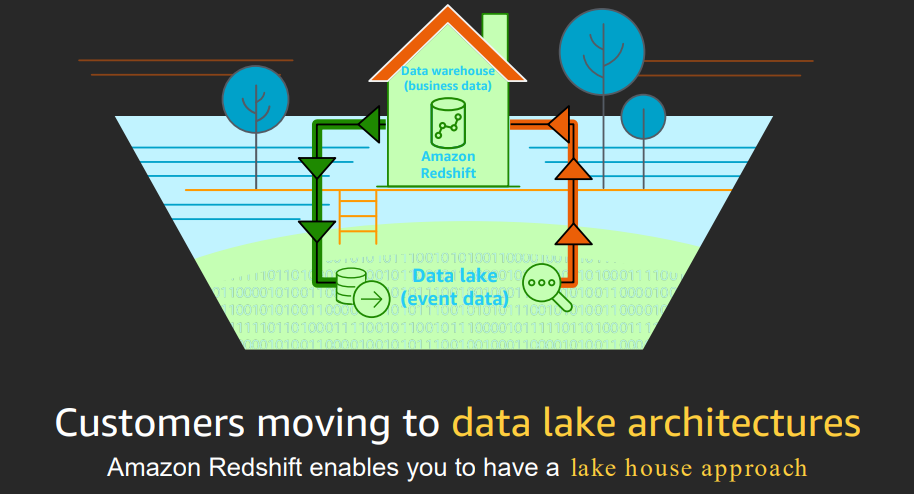
Developed on Postgres SQL, added OLAP.
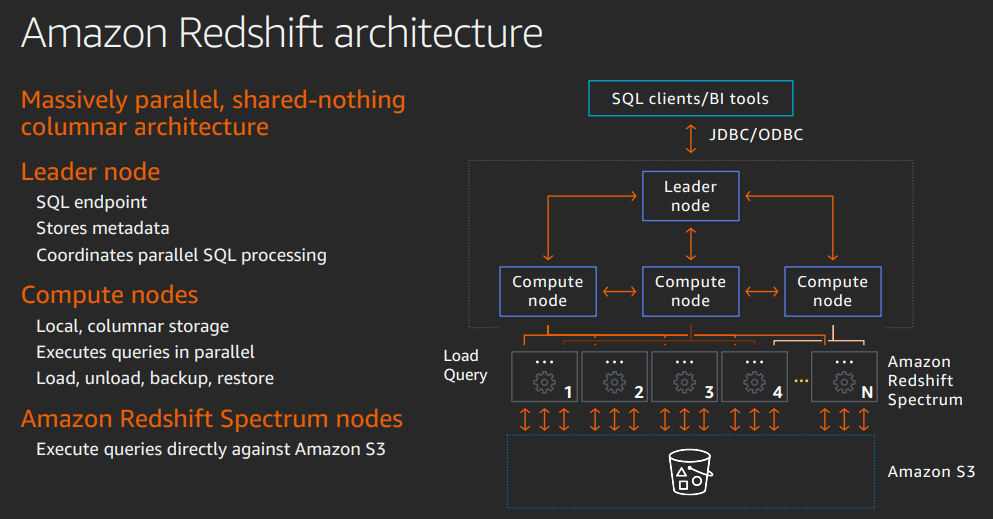
Lots of concepts to store data in appropriate configuration
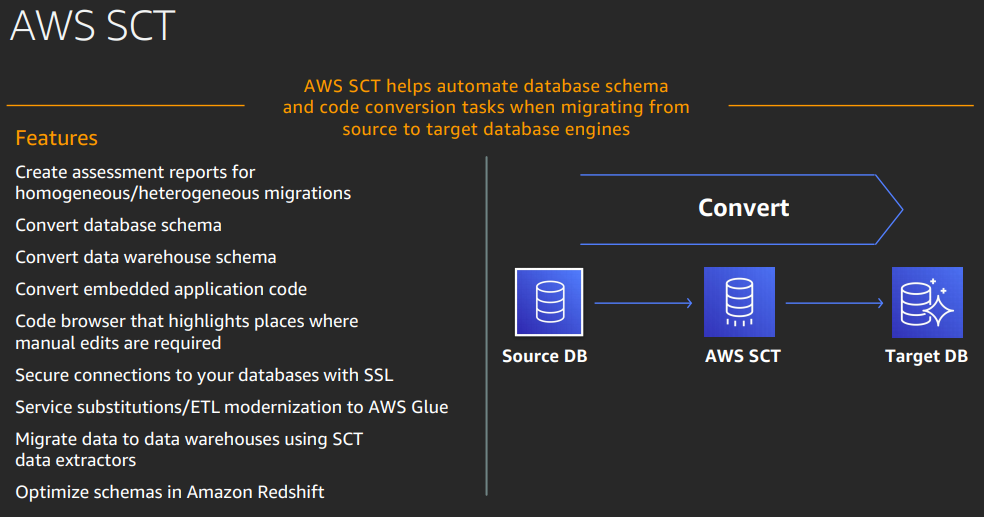


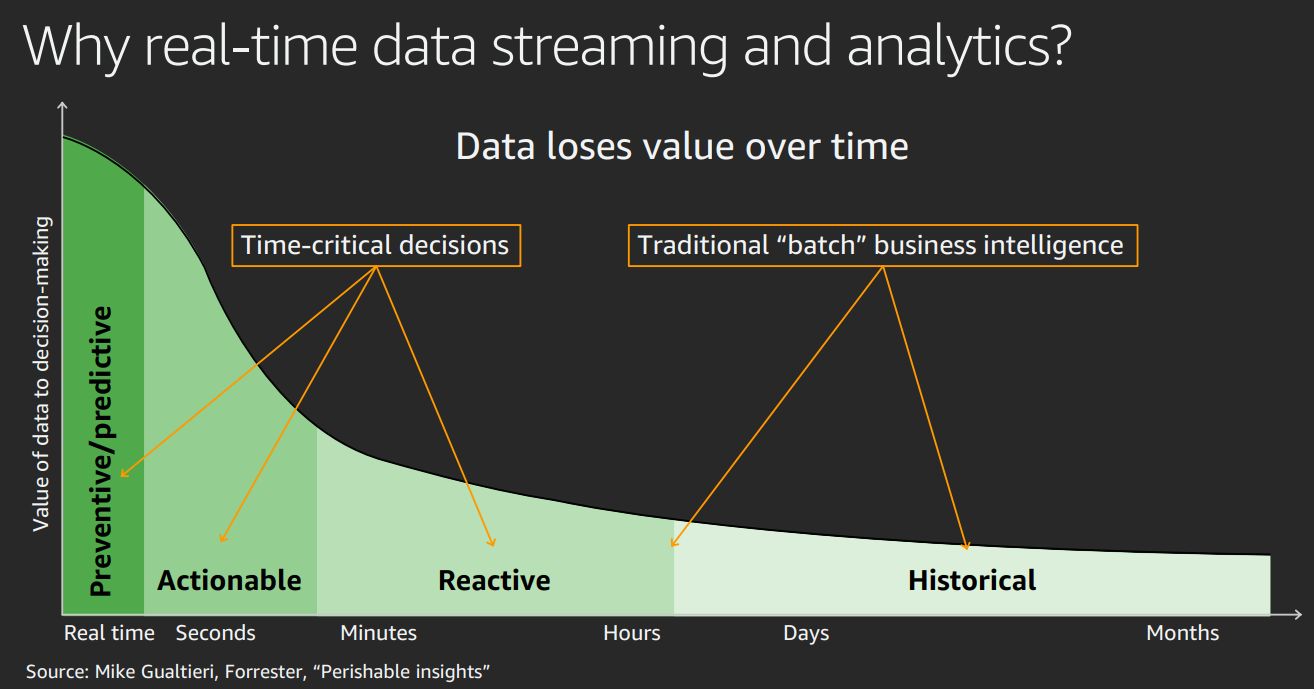
Use Data streams to react to application events
Process quickly
Buffer to enable parallelization
Use data streams for real time architecture.

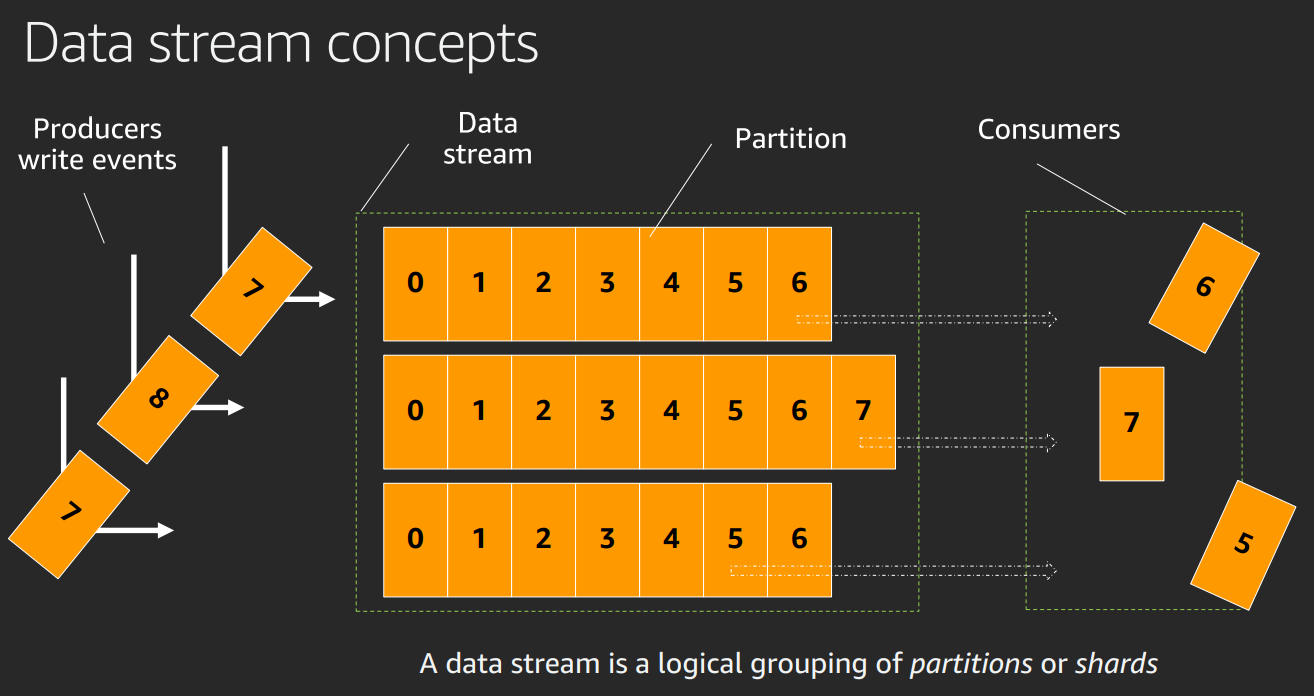
Producers and consumers and decoupled.
Easily collect store process anaylise in real time.
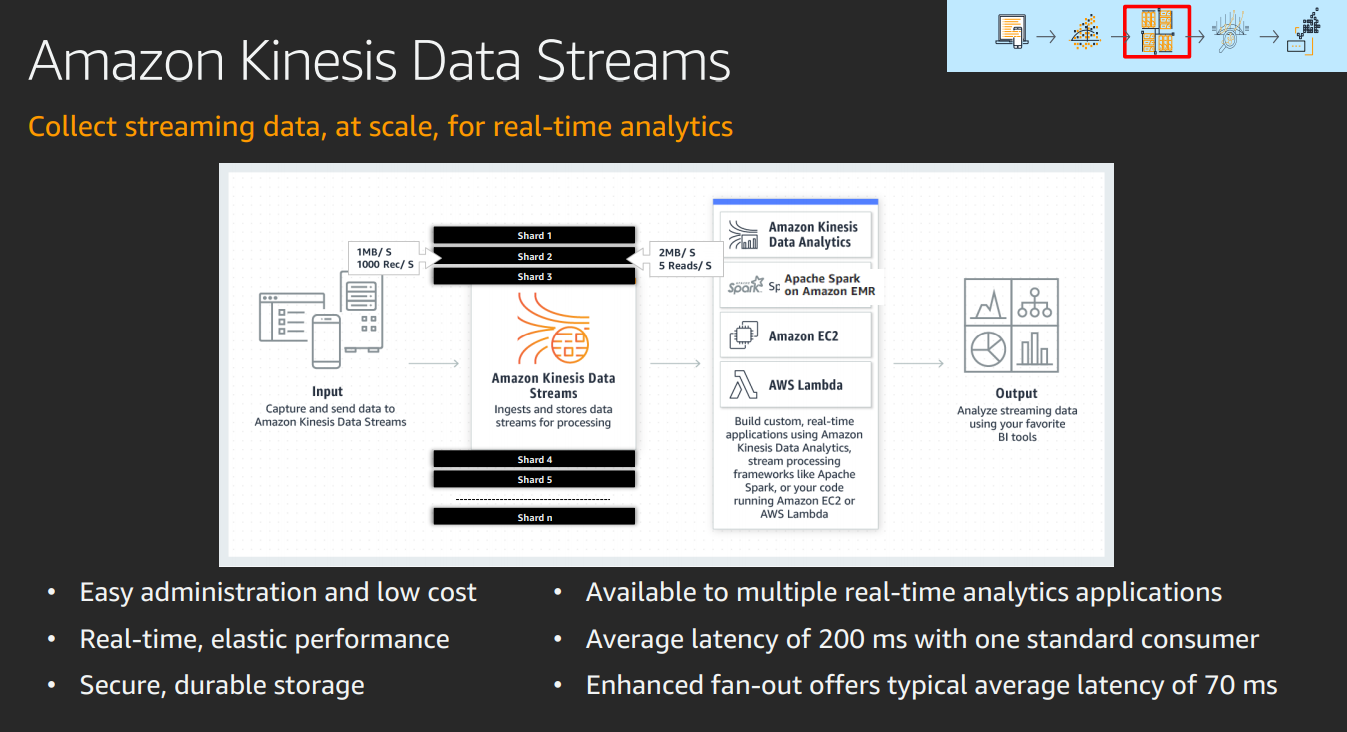
End to end platform
Integrates with ML
Gives easy analysis tools
Feed data stream to Rekognition
or sageMaker
Can play back online.