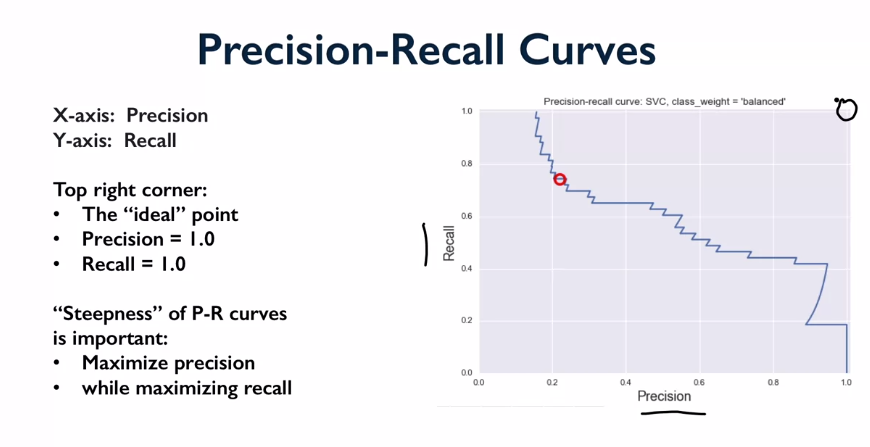
X is precision, Y is recall.
Ideal classifier would be perfect for both. Shows trade off between both. Apply varying decision boundary to get the curve. As precision goes up, recall goes down. Jagged: discrete counts used in calcs, so as you get to the edges the discrete counts cause big jumps as goes from 2 to 1.
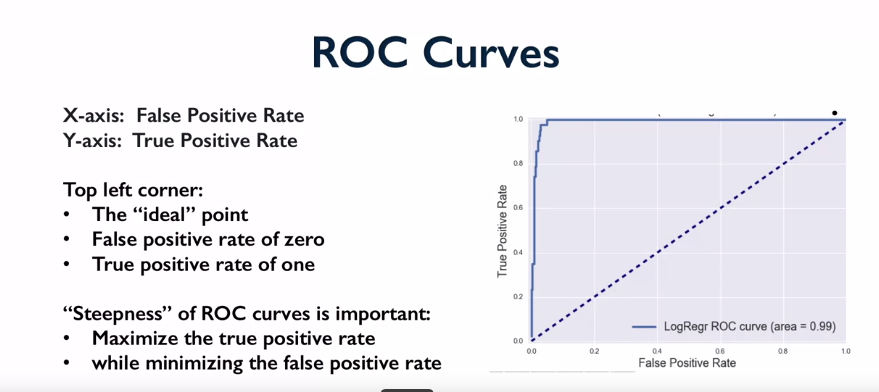
Receiver operating characteristic curves used for performance of a binary classifier.
X is false positive rate, y is true positive rate. Upper left is perfect. Dotted line is baseline. Look at area underneath the curve to maximise this on ROC curve.
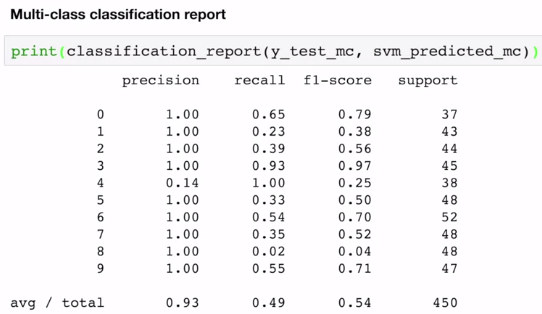
Collection of true vs predicted binary outcomes, one per class. Confusion matrix for multi class and Classification reports work well.
Various measures to average multi class results, and imbalanced class issues. Also multi label is more complex than multi class evaluation.
Look at confusion matrix for an insight into whats going wrong.

create with:
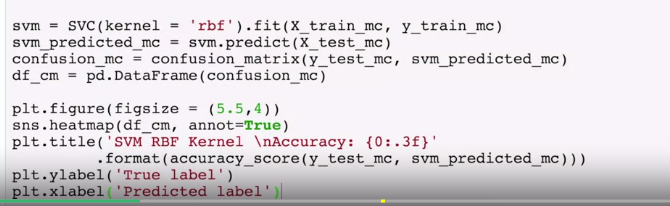
A bad model example: use heatmap to show errors
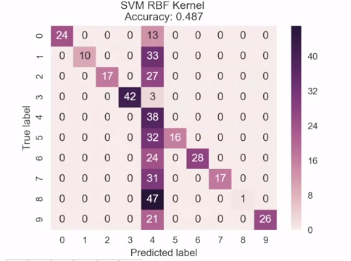
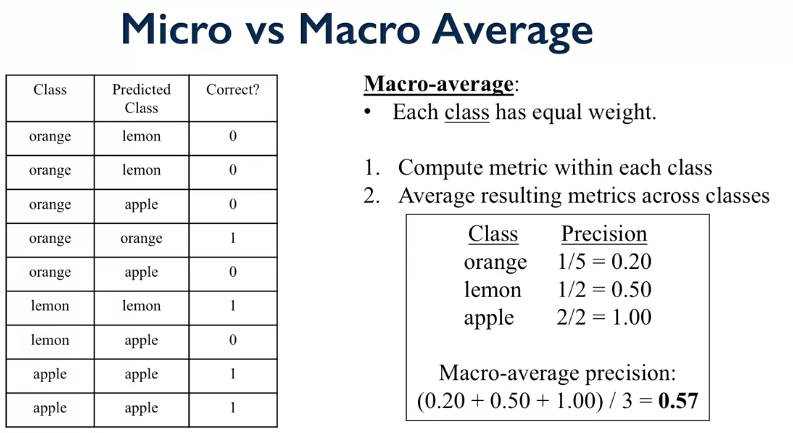
Each class has equal weight. Compute e.g. precision for each class (true positive / ). Then average over all classes. If e.g. loads from one class, equal weight with other classes.
Each instance has equal weight.


Could look at predictions and categorise the error. But in practice, not so useful. Typically r2 score is enough.
provided by scikit learn. e.g. flat line for one variable vs y flat, quantile, etc.