Define a problem
a. Define a success metric
Data
a. Does the model need to work in real time?
b. Does the model need to be trained in real time?
c. Is there an inconsistency between train and test data
Evaluation
a. Train test split at random assumes data is homogenous. Probably not. Mayb slpit by time instead.
b. Baseline model
Features
a. Choose good ones
b. Remove redundant ones
Modelling
a. Does it need to be interperable?
b. How to tune
Experiment
a. Go into production and evaluate and update quickly
Have a standard boilerplate way to process data to investigate. Saves lots of reengineering.
e.g. Qualitataive / quantitative cols
Null values
correlations
Uac / roc to score
Classification_report to show the precision of models
Xgboost is new and good
Random forests -- tree decision, good at lots of things.
Use ridge not Lasso as lasso removes some features -- try Eslatic net regression
Blueprint technologies flow chart to find best model. Also one on scikit
Mean absolute error is a good accuracy test.
Move to K fold
Open grid cv to go through parameters. https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html
in order of evolution:
Grid Search (e.g. GridSearchCV) does cross valiation and parameter optimisation.
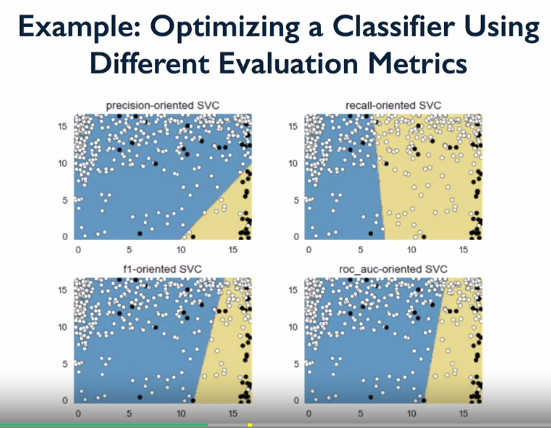
Default measure used is accuracy, but can pass an evaluation metric as scoring parameter.
Get a different decision boundary when using different scoring pameters to tune the model.
Just using cross validation is prone to data leakage, test data used partially for model selection. Hold out a final test set, not used in cross validation.
In practice, use 3 data splits

Select an evaluation metric which suits the particualar application.
